Everything you Need to Know about Machine Learning and Lambda Automation
Jade Consultancy Team
Jul 10, 2017
Machine learning is bringing a lot of buzz to the analytics world…and rightly so! Its advanced abilities can deliver predictions that drive real business value. However, all this hype also comes with a lot of confusion. Rushed implementations without proper planning for operational aspects of machine learning are a major issue when it comes to execution. So, let’s back up a bit and review how machine learning algorithms function before elaborating more on these issues.
The diagram below explains at a high level how machine learning algorithms function.
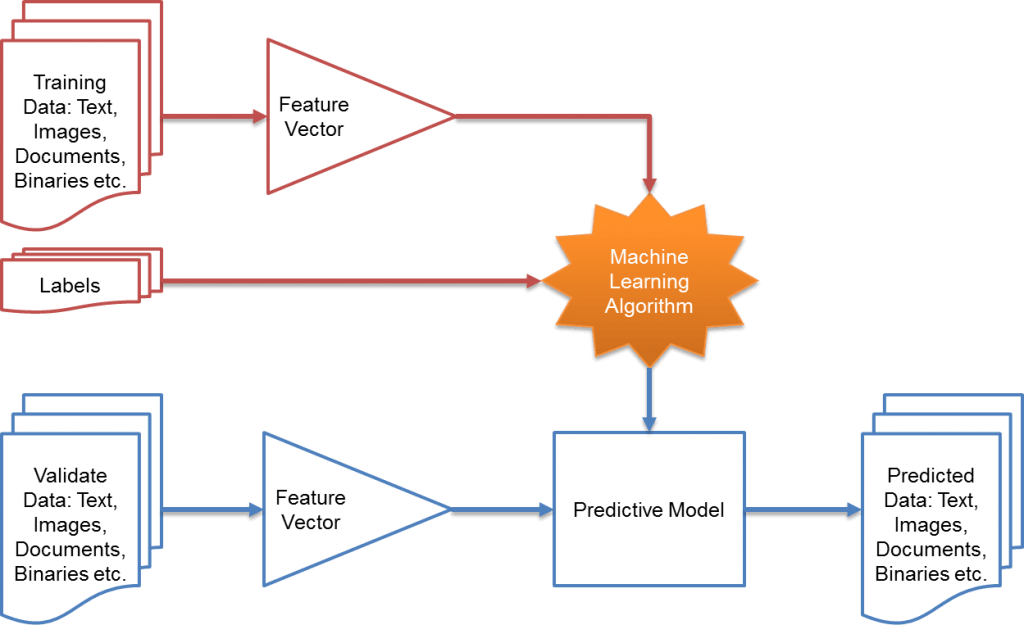
In a nutshell, the machine learning algorithm ingests historical data with some metadata to build a “Predictive Model”. The Predictive model is a function (algorithm) that can ingest fresh data and predict values for target fields. Predictive models can be built in many different platforms like R, SAS, SPSS and Mahout using various algorithms (filtering, clustering or classification). Once built and tested, models can be deployed in production for continuous prediction purposes.
The Problem
This is when the reality of operational issues starts to surface. The Most frequent question we get from our clients during machine learning implementations is, “How do we keep changing the model with new data?” The problem is, if you keep changing the model continuously with new incoming data, how do you make sure that the new model still meets the error and efficiency rates needed for business?
Lambda Automation
Our answer to this question is Lambda Automation. Let’s look at a diagram before we delve into what Lambda Automation (architecture) is all about.
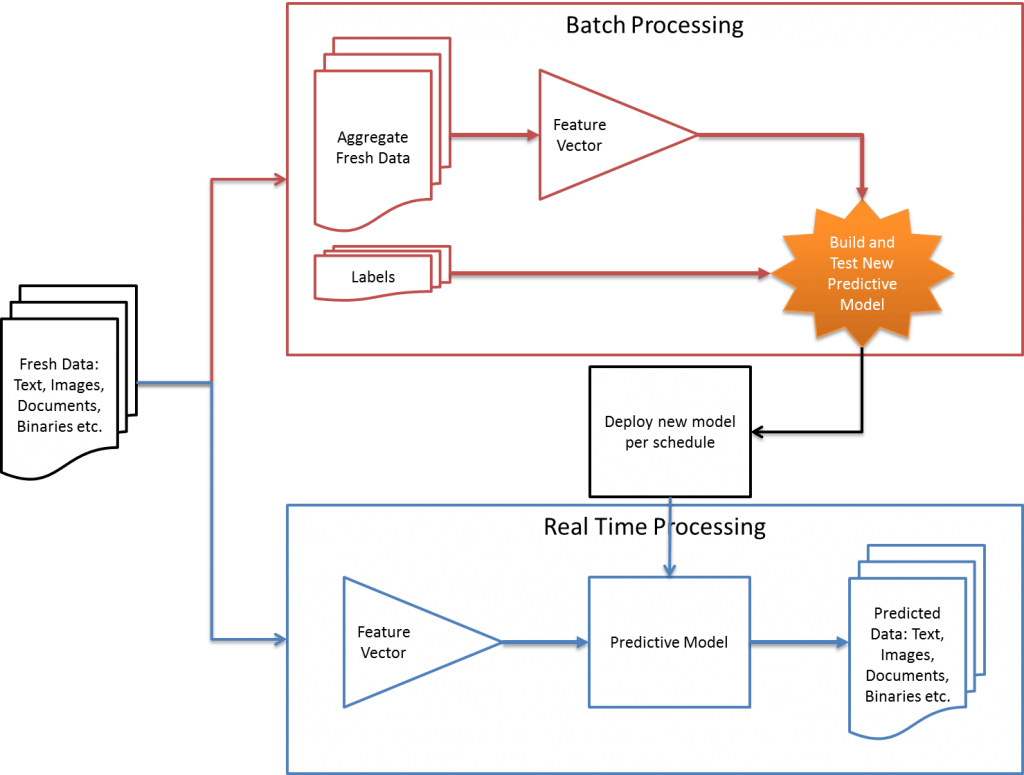
It may sound strange but, Lambda Automation has nothing to do with mathematical lambda functions. Basically, it is a process of automatically validating new predictive models and deploying to production if it meets requirements of error rate and efficiency. Lambda automation architecture creates two flows of fresh data:
- Real time flow: Fresh data is sent to a real-time flow predictive model that is deployed in production for continuous or on-demand predictions. This flow is unchanged from traditional machine learning structure where fresh data is continuously flowed to the deployed model.
- Batch processing flow: Lambda automation introduces one more data flow (stream) to a batch processing engine. This engine aggregates new data to existing historical data, creates a new predictive model from newly aggregated data, performs validations, and deploys a new model to production if it meets business requirements. Batch processing engine also takes scheduling into account not to change predictive results abruptly during business critical work hours. It can be configured to deploy at off-hours or even in real-time depending on business needs and fault tolerance.
To tie everything together we’ve gone over, let’s review the benefits of Lambda Automation.
Read the success story: RMA Portal and Warranty Automation
Benefits of using Lambda Automation
- The Predictive model is refreshed regularly with new data providing real-time business value and decision making capabilities.
- The automation of model validation and deployment processes. These processes remove the administrative burden and chance of error.
- Analytics on analytics. The Lambda automation process allows us to perform analytics on the accuracy of predictive models, areas of improvement in algorithms, incoming data quality, and usage stats.
Subscribe to our email Newsletter
Popular Posts





About the Author